
L16 – Logic I: Languages and Automata
5,703字
24–36 分钟
Formal language
Definition
- An alphabet is a finite set .
- Elements of an alphabet are called characters.
- A string over is a finite sequence of characters from .
- A (formal) language over is a set of strings
Notations:
- The empty string containing no characters is denoted .
- The set of all strings over is denoted .
- So a language over is a subset .
Example
- .
Example
- .
- is the language of palindromes over .
- .
Example
Programming codes, mathematical expressions, logic formulas.
Formal language vs Natural language
| Natural language | Formal language |
|---|---|
| Natural, organic, evolving. | Artificial, designed, fixed. |
| Ambiguous, descriptive. | Well-defined, prescriptive. |
| Flexible, redundant. | Minimalist, structured. |
| Semantics (meaning) is most important. | The form is most important. |
Key question:
How to efficiently describe a language?
(not by listing all its strings).
Regular language
- Union.
- Concatenation.
- Power. .
- Kleene closure.
Definition: The collection of regular languages can be defined recursively as follows:
- The empty language and for are regular languages.
- If is a regular language, so are and .
- If and are regular languages, so are and .
Deterministic finite automaton
A mathematical model of computation. Can be used to determine whether a string is within a language.
Definition: A deterministic finite automaton (plural automata) consists of a set of states and a transition function . A unique state is designated as the initial state, and some states are designated as the final states.
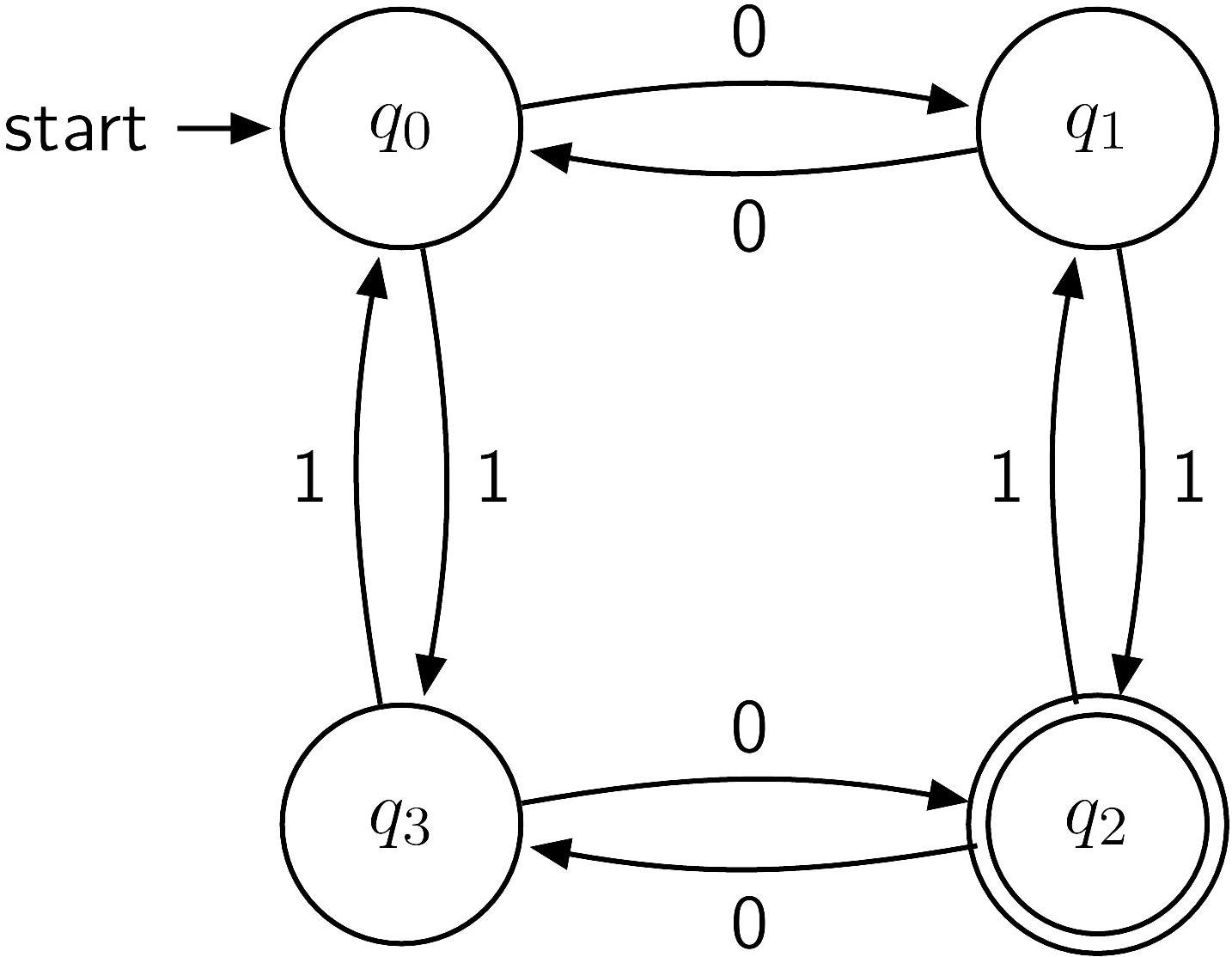
An automaton runs on an input string and answers YES or NO.
- Initially, the automaton is in the initial state .
- After steps, the state of the automaton is denoted .
- At the -th step, the automaton reads the -th character of , then transitions from the state to .
- After steps, the string is accepted if is a final state, and rejected otherwise.
Definition: The language of an automaton is the set of strings accepted by this automaton.
Theorem: A language is regular iff it is the language of a deterministic finite automaton.
Example
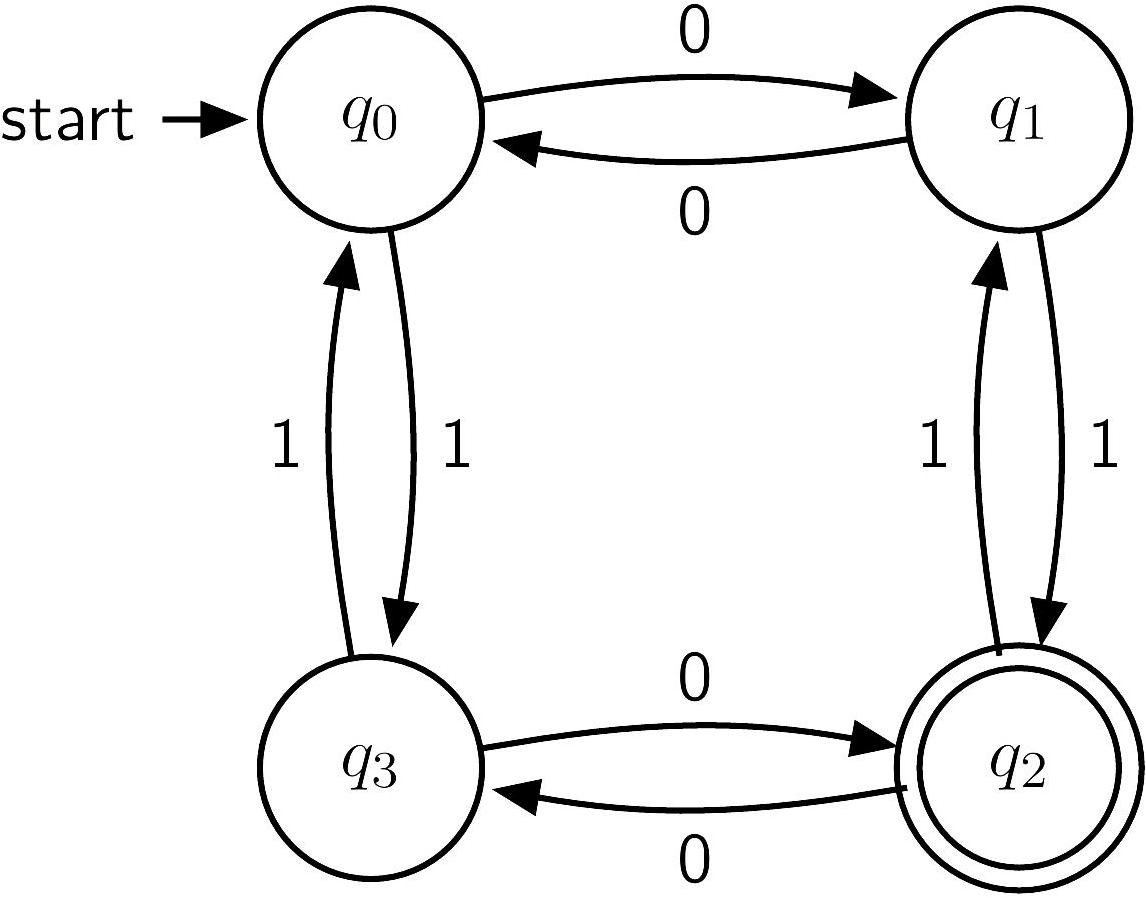
- The string
010110is accepted. - The string
101000is rejected. - The string
11011100is?
Example
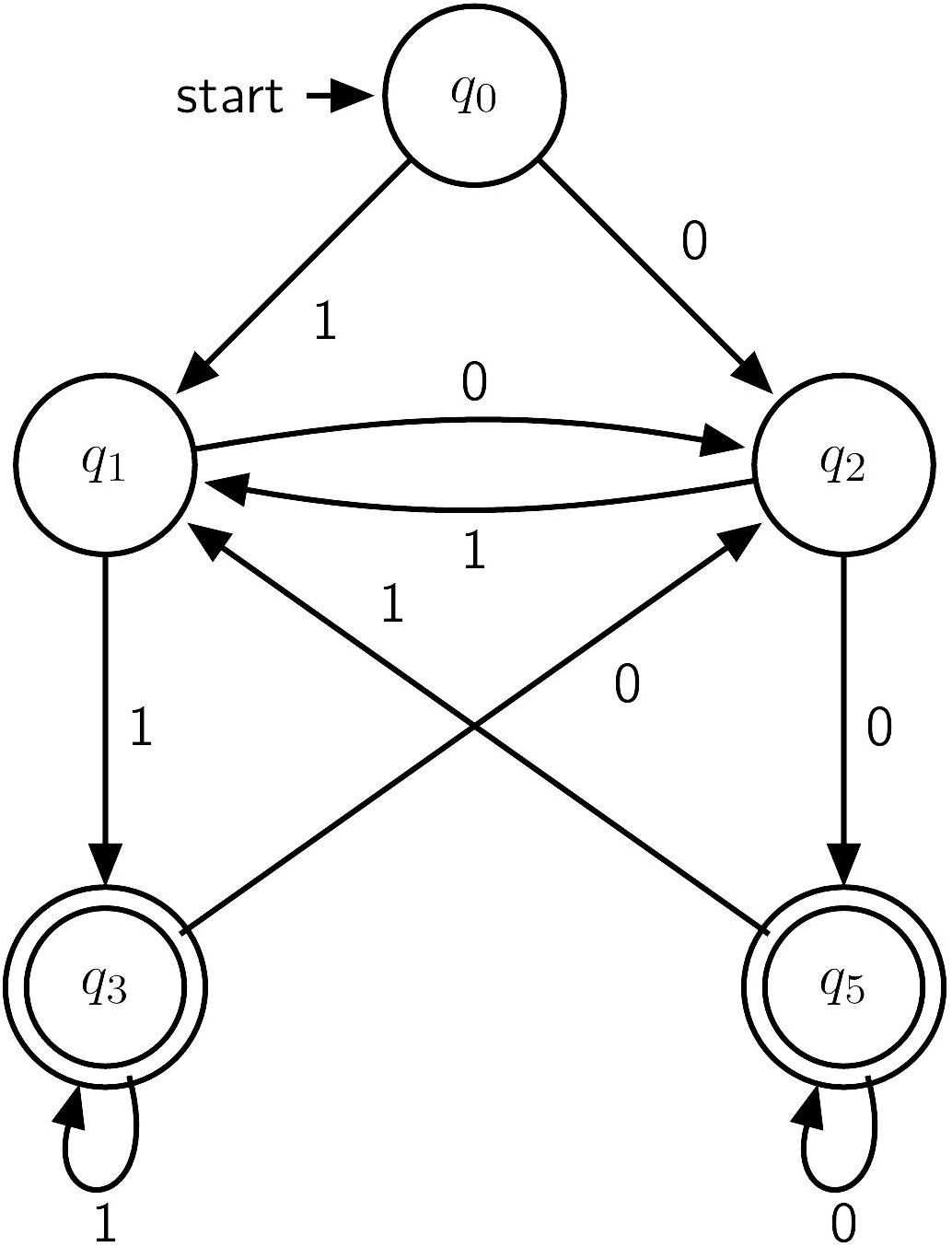
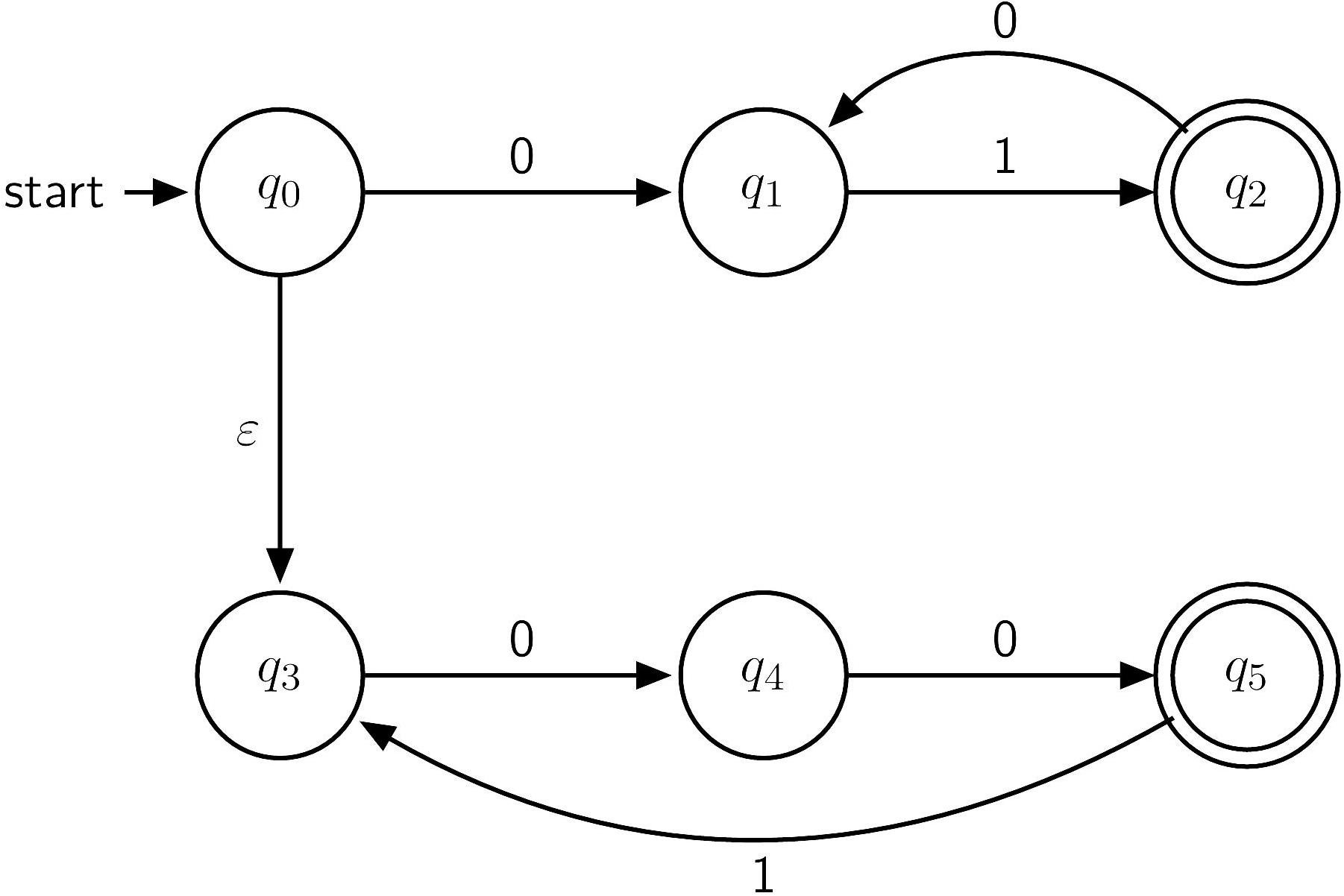
Nondeterministic finite automaton
In an NFA,
- For a state-character pair in , there might be zero or several possible transitions (non-deterministic).
- There is an -transition that can be followed for any number of times without consuming any character in the input string.
- The input string is accepted iff there exists a sequence of transitions that leads to a final state.
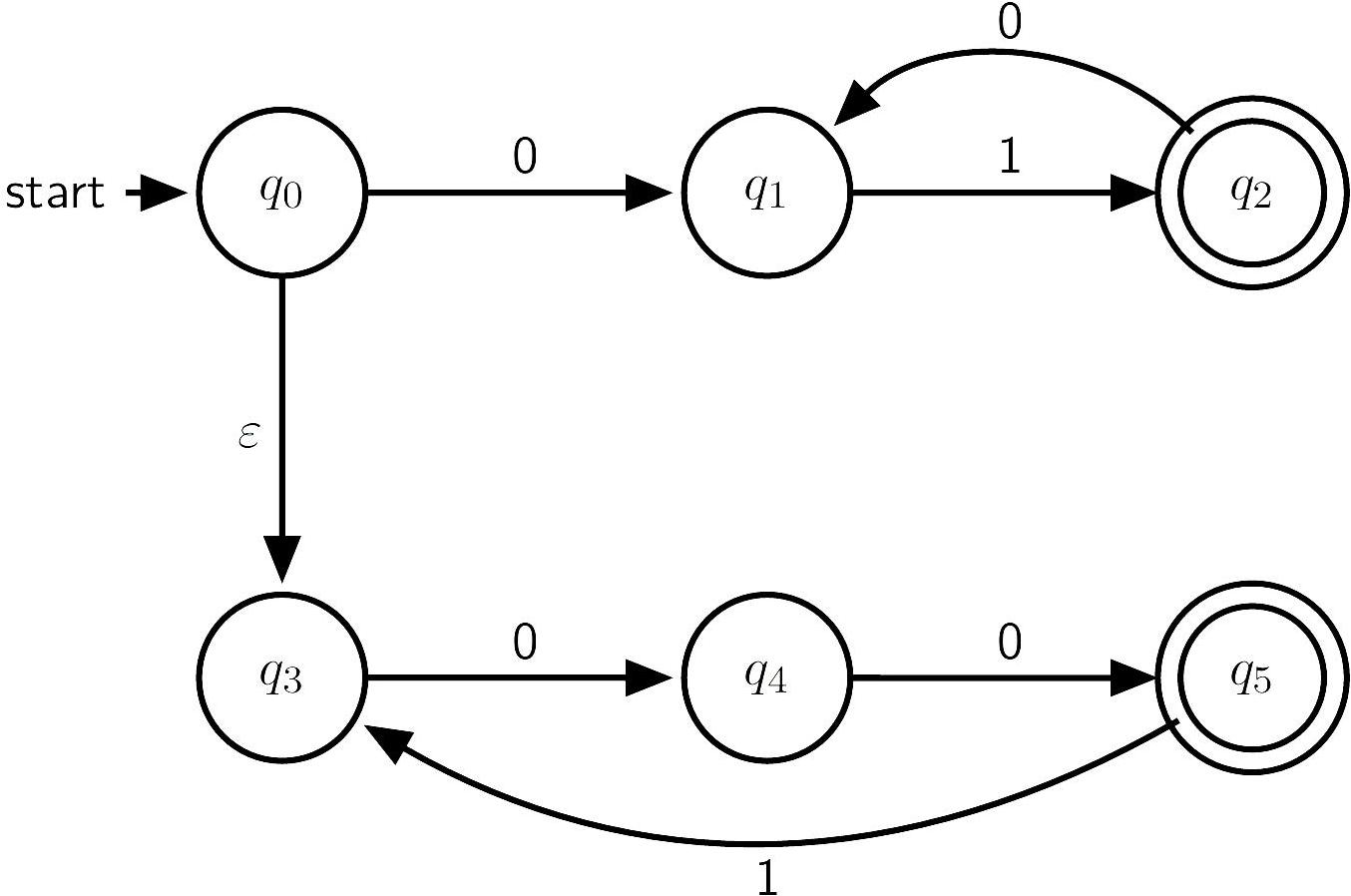
Example
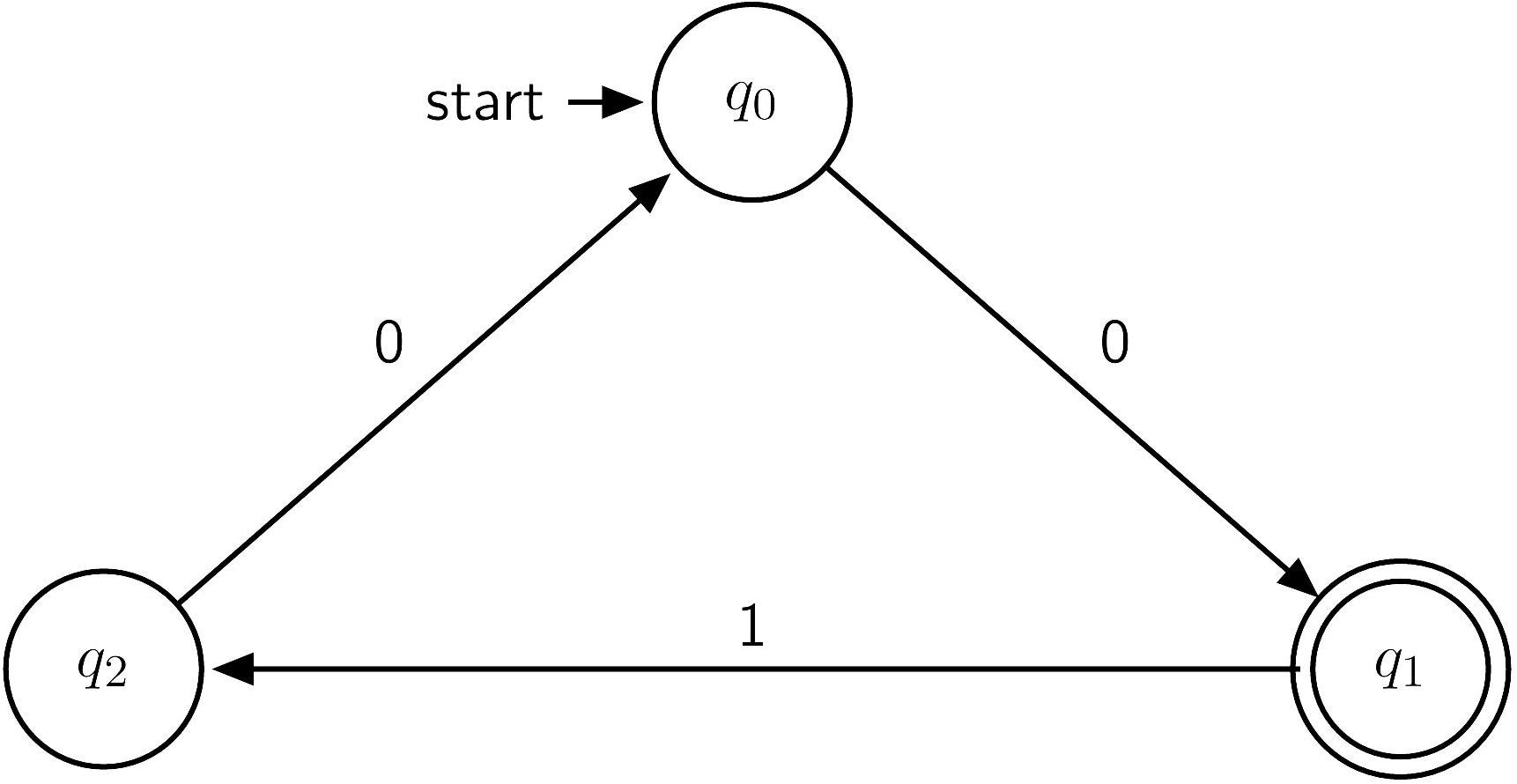


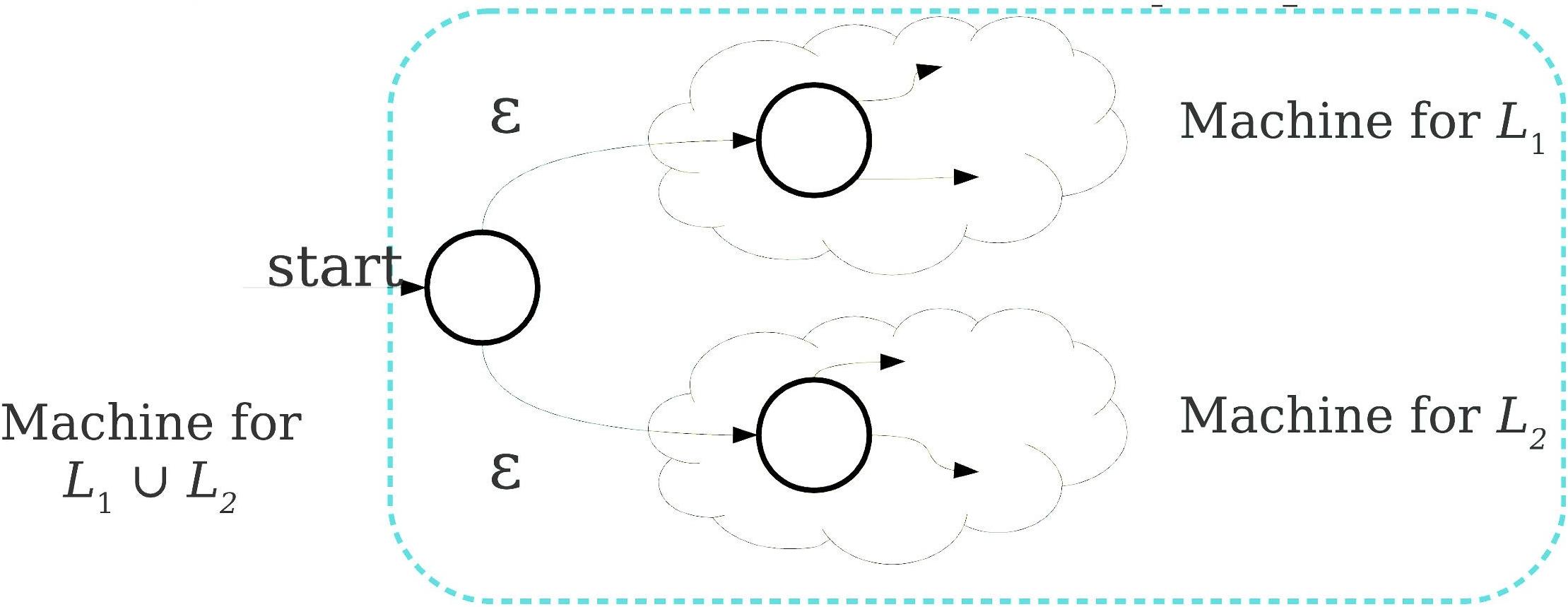
Theorem (NFA=DFA) A language can be accepted by a DFA iff it can be accepted by an NFA.
Proof (omitted) by powerset construction.
Example
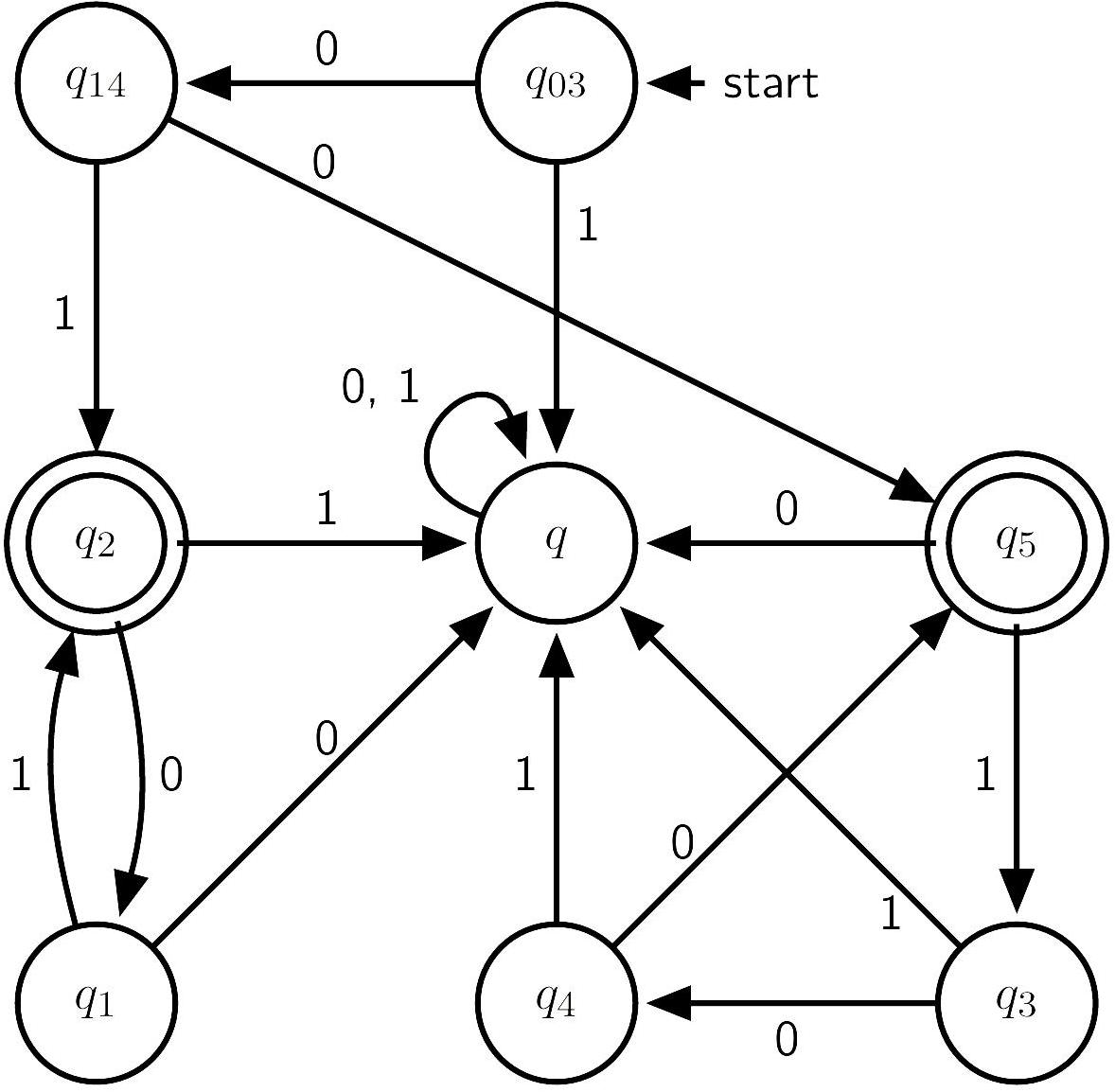
Theorem: A language is regular iff it is the language of a NFA.
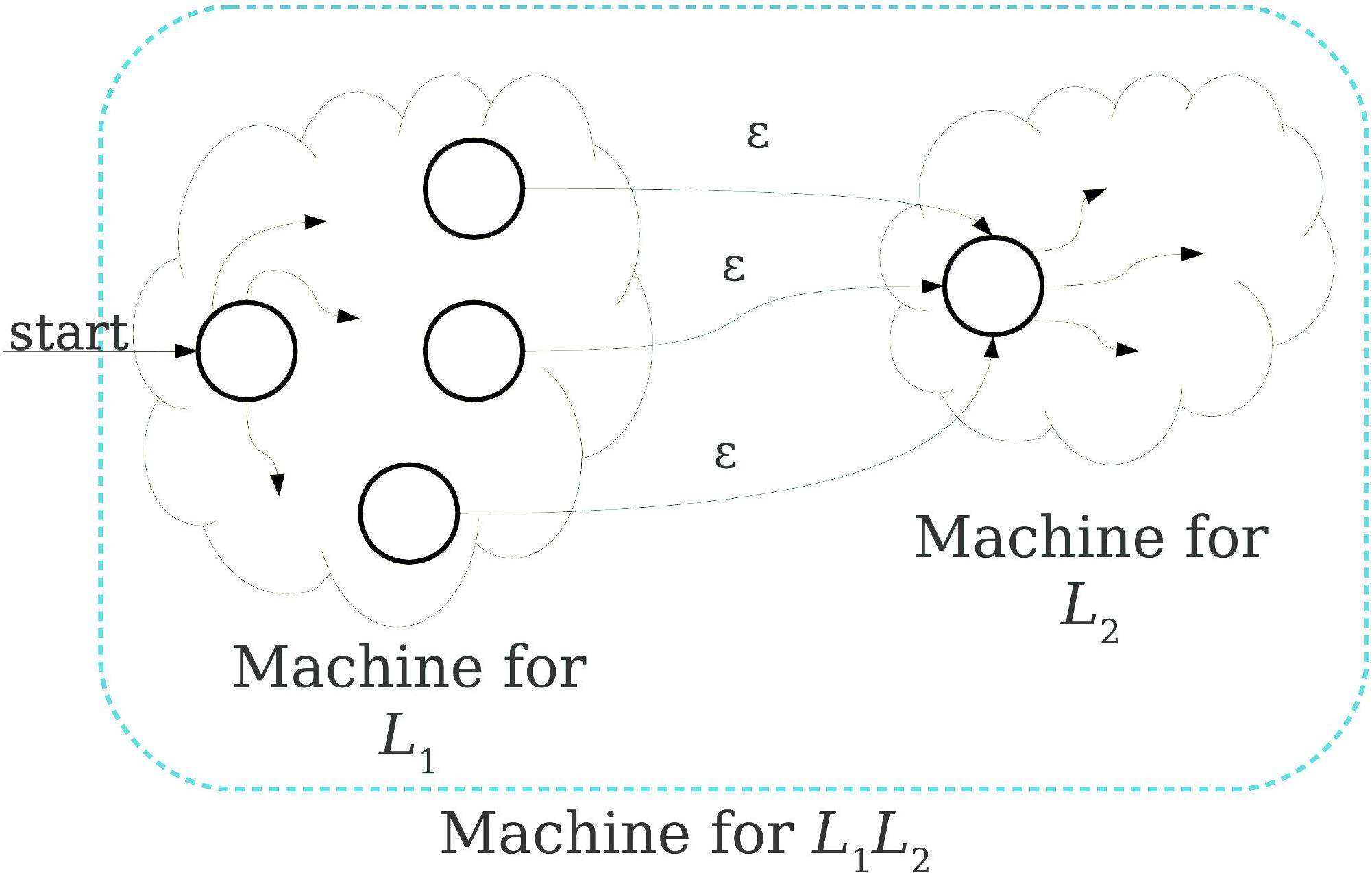
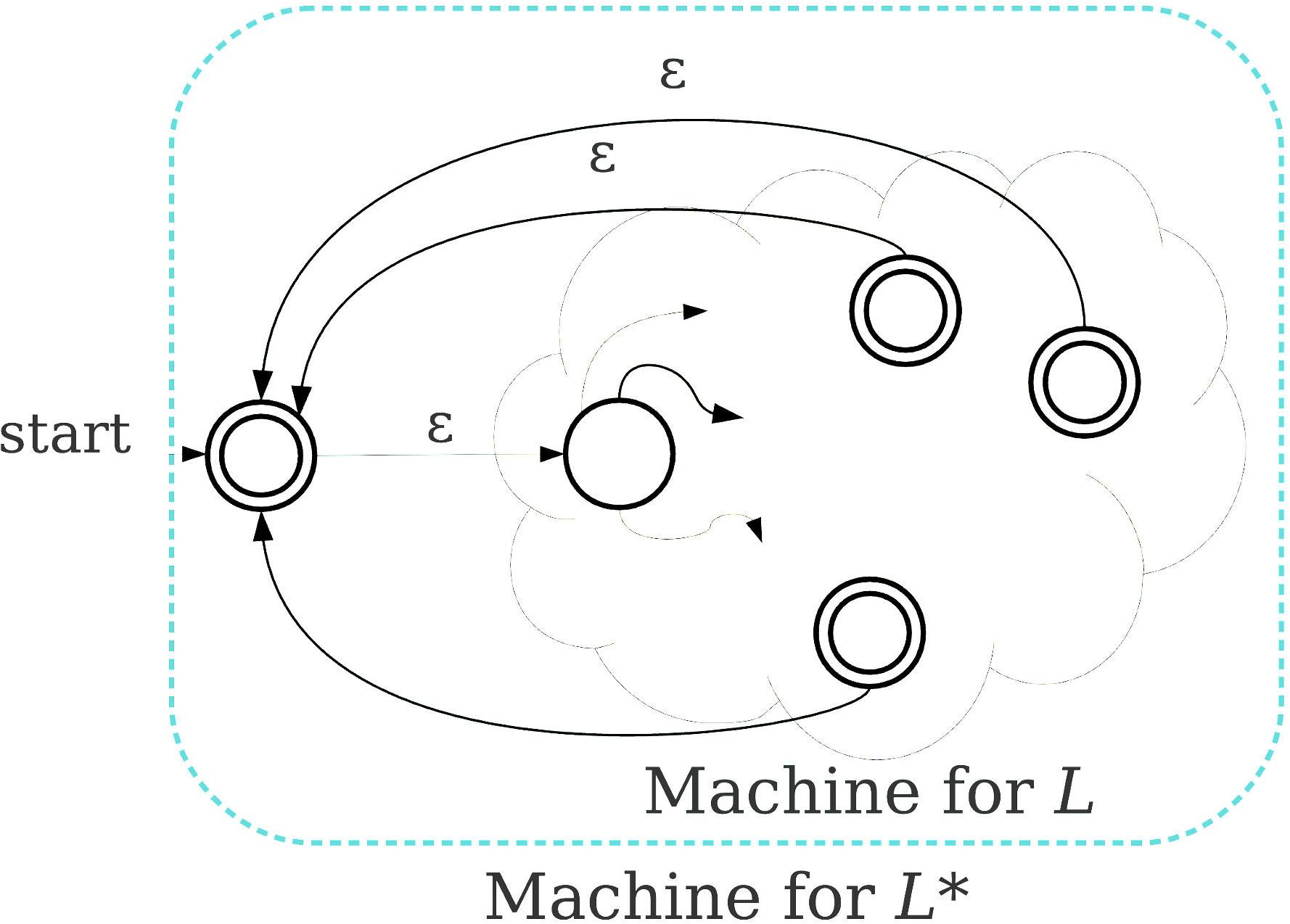
Formal grammar
Definition: A formal grammar consists of
- A set of terminal symbols.
- A set of nonterminal symbols disjoint from .
- A set of production rules of the form
- A distinguished start symbol.
Example:
- , .
- , , .
Regular grammar
Definition: A (right-)regular grammar is a formal grammar such that each production rule is of the following forms
- .
- .
- .
where and .
Theorem: A language is regular iff it can be generated by a (right-)regular grammar.
If we replace the last production rule by , we obtain a left-regular grammar, equivalent to the right-regular grammar.
However, if both and are included in the production rules, the language is not regular.
Regular expression
A convenient and popular way to describe a regular language. Let be a regular expression, we use to denote the language it describes.
Regular expressions (regex) start with the atomic regular expressions.
- the empty language , .
- the empty string , .
- for , .
Then we combine regular expressions in the following ways (in the order of increasing precedence!).
- Or (union of languages).
. - Concatenation.
. - Kleene closure.
.
Example
(0|1)*00(0|1)*,00.- , .
1*(0|)1*,1*0?1*.[A][A]*(.[A][A]*)*@[A][A]*.[A][A]*(.[A][A]*)*,[A]+(.[A]+)*[A]+(.[A]+)+.
By definition
Theorem: A language is regular iff it is the language of a regular expression.
The set of regular expressions is itself a language, but not a regular language.
POSIX regex standard
This is the syntax used by many practical tools such as grep. It is a convenient shorthand for writing regular languages.
.matches any single character.[abc]matches one character chosen from the set{a,b,c}.[A-Z]matches one uppercase letter in the rangeAtoZ.R+means one or more copies ofR.R?means zero or one copy ofR.R*means zero or more copies ofR.(R)groups a subexpression.R|Smeans eitherRorS.
Example[A-Za-z]+@[A-Za-z]+\.[A-Za-z]+ matches an email pattern.
Context-free grammar
Definition: A context-free grammar is a formal grammar such that the lhs of each production rule is a single non-terminal symbol. A language is context-free iff it can be generated by a context-free grammar.
Example
- , , .
- , , .
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



回文那个例子挺直观的
幂集构造的证明有点跳步啊
DFA图例那部分有点意思
正则表达式居然不是正则语言?
我也被这个绕进去了
ε转移确实容易让人晕圈,CFG那章也够呛
NFA的ε转移总觉得有点绕
我也觉得有点绕,理解中
Kleene闭包那符号老记不住
POSIX正则这块儿蛮实用的
形式语言和自然语言对比有意思
CFG那块儿看得我有点懵
我也卡在这了
那个邮箱的正则写起来真的头大
DFA状态图看着挺直观的
我也觉得,图解方便很多
回文那个例子好直观
NFA转DFA那个幂集构造法真的心累
左右正则混用直接寄,踩过坑
形式语言和自然语言的对比蛮有意思的
正则表达式那块儿终于搞懂了,原来Kleene closure是这么回事
最后那个上下文无关文法看着就头大
同感,看到那块直接跳过
正则表达式那部分例子挺实用,直接拿来写校验
回文用栈实现更直观,有限状态机搞不定无限回文
DFA图确实比看定义好懂,画出来就明白了😭
NFA转DFA的powerset construction,考试考了直接放弃
这课跟计算理论有重叠,但这边更强调自动机模型,侧重点不同
那个[A]+是重复一次或多次,相当于[A][A]*,看懂了没?
正则表达式优先级Union最低,Kleene star最高,记错就写错
S→aSa这种递归规则,一眼就能看出结构,写解析器好用
DFA图好直观啊
正则表达式真的省事👍